
Einführung
Die manuelle Rechnungserstellung zum Testen von Finanzanwendungen wie Buchhaltungssoftware und Zahlungsabwicklungsplattformen ist ein arbeitsintensiver Prozess, der viel Zeit und Ressourcen in Anspruch nimmt und gleichzeitig die Gefahr birgt, dass sensible Daten preisgegeben werden. Buchhaltungssoftware wie Xero oder Bexio benötigen beispielsweise realistische Rechnungsdokumente, um die Datenextraktions- und Analysefunktionen zu testen. Unsere automatisierte Pipeline, die auf Large Language Models (LLMs) wie Gemini und Claude basiert, generiert realistische Rechnungen, die den regionalen Compliance-Standards entsprechen. Die manuelle Erstellung von 100 konformen Rechnungen ist praktisch undurchführbar. Diese Aufgabe wird auf 50 Stunden geschätzt, wobei von 30 Minuten pro Rechnung für die Datenerfassung, Formatierung und Konformitätsprüfung ausgegangen wird. Dadurch sind Entwicklungsteams gezwungen, einen kleinen, statischen Satz von Testdaten wiederzuverwenden, wodurch ein System nicht den vielfältigen Szenarien ausgesetzt ist, denen es in der Produktion ausgesetzt sein wird.
Unsere Pipeline verändert diese Dynamik. Der wahre Vorteil liegt nicht in der Beschleunigung eines alten Prozesses, sondern darin, eine neue Möglichkeit zu schaffen: die Fähigkeit, umfangreiche und konforme Datensätze auf Abruf zu generieren. Auf diese Weise können Entwickelnde kontinuierliche Tests mit aktuellen Daten für jeden Build durchführen, komplexe Randfälle einem Stresstest unterziehen und täglich dynamische, wirkungsvolle Kundendemos erstellen. Durch die Automatisierung dieses Workflows beseitigt unsere Lösung auch manuelle Fehler (z. B. falsche Mehrwertsteuersätze, falsch formatierte IBANs) und Compliance-Risiken, die mit einem manuellen Ansatz einhergehen. Das Ergebnis ist ein wichtiger Wandel in der Qualitätssicherung: Anstatt Software zu veröffentlichen, die anhand weniger vorhersehbarer Fälle getestet wurde, können Teams jetzt Finanzanwendungen bereitstellen, die sich als robust, konform und widerstandsfähig gegen ein breites Spektrum realer Szenarien erwiesen haben.
Warum synthetische Daten wichtig sind
Finanzanwendungen wie Buchhaltungssoftware und Zahlungsplattformen benötigen zuverlässige Testdaten, um sicherzustellen, dass sie korrekt funktionieren und die regulatorischen Anforderungen erfüllen. Wie wir bereits festgestellt haben, skaliert die manuelle Erstellung synthetischer Daten nicht. Echte Kundendaten sind auch keine Lösung. Selbst wenn Kunden ihre Zustimmung geben, können die Sicherheitsmaßnahmen, die zur Verhinderung von Sicherheitsverletzungen und zum Schutz der Datenintegrität erforderlich sind, dazu führen, dass Testumgebungen unnötig komplex und schwer zu verwalten sind. Die Generierung synthetischer Daten löst dieses Problem und bietet gleichzeitig wichtige Vorteile:
Skalierbare Leistungs- und Stresstests: Die Pipeline ermöglicht die Generierung von Daten mit einem Volumen und einer Geschwindigkeit, die manuell nicht repliziert werden können. Dies ist unerlässlich, um Systemgrenzen unter Stress zu testen und Leistungsengpässe zu erkennen. Sie können beispielsweise einen Abrechnungszyklus zum Monatsende mit Tausenden von Rechnungen simulieren, um den Durchsatz des Zahlungsgateways zu testen, oder ein einzelnes Benutzerkonto mit über 10.000 Rechnungen auffüllen, um zu überprüfen, ob Benutzeroberflächenfunktionen wie Suchen, Filtern und Paginierung leistungsfähig bleiben und sich bei realistischer Belastung nicht verschlechtern.
Durchgängige Überprüfung der Datenintegrität: Eine einzige synthetische Rechnung dient als konsistente „Informationsquelle", um den gesamten Datenweg in Ihrem Anwendungsstapel zu validieren. Beispielsweise kann eine generierte Rechnung über 99,50 CHF gleichzeitig verwendet werden, um:
- Die Genauigkeit der Analyse zu testen, indem sichergestellt wird, dass Ihr Rechnungsparser alle Felder (Betrag, Datum, Lieferant, Einzelposten) korrekt aus der PDF-Datei extrahiert.
- Das visuelle Rendern und Formatieren in der Frontend-Benutzeroberfläche zu überprüfen.
- Sicherzustellen, dass die Backend-API den Betrag korrekt verarbeitet und präzise in der Datenbank speichert.
- Zu bestätigen, dass das Buchhaltungsmodul die entsprechende Steuer (z. B. 8,1%) korrekt berechnet und im Hauptbuch verbucht.
Dadurch wird eine nahtlose Datenintegrität vom Pixel bis zum Ledger gewährleistet – eine bekanntermaßen schwierige und fehleranfällige Aufgabe, wenn für jede Ebene separate, getrennte Daten verwendet werden.
Umfassende Risikominderung: Synthetische Daten eliminieren die Risiken, die mit dem Umgang mit echten Kundeninformationen in Testumgebungen verbunden sind. Dieser Schutz geht über die einfache Einhaltung gesetzlicher Vorschriften wie der DSGVO und des schweizerischen FADP hinaus. Selbst wenn Kunden der Verwendung ihrer Daten für Tests ausdrücklich zustimmen, bestehen die betrieblichen Risiken eines versehentlichen Datenlecks, einer falsch konfigurierten Umgebung oder eines unbeabsichtigten Kontakts mit einem Drittanbieter-Service fort. Durch die Erstellung strukturell realistischer, aber völlig fiktiver Daten sorgt unser Ansatz dafür, dass die Testumgebung von Grund auf sicher ist und die Entwicklungsaktivitäten vollständig von vertraulichen Produktionsinformationen entkoppelt werden.
Dieser Ansatz verwandelt die Rechnungserstellung von einer zeitaufwändigen manuellen Aufgabe in eine automatisierte Ressource, die die Entwicklungszeiten beschleunigt und gleichzeitig die Datensicherheitsstandards einhält.
Überblick über den Arbeitsablauf
Die in TypeScript implementierte Pipeline folgt einem strukturierten Ablauf von der Schemadefinition bis zur Erstellung von Demopaketen und nutzt dabei die Funktionen eines LLMs. Dieser Workflow generiert synthetische Rechnungsdaten, die nicht nur zufällig sind, sondern auch einer Reihe von realen Standards entsprechen, um deren Nützlichkeit und Realismus sicherzustellen. Insbesondere erzwingt die Pipeline die Einhaltung der Vorschriften in mehreren wichtigen Bereichen:
Struktur- und Formatkonformität: Sicherstellen, dass Daten wie IBANs, QR-IBANs und Referenznummern ihren offiziellen Spezifikationen entsprechen (z. B. ISO 13616 für IBANs).
Regionale und rechtliche Kohärenz: Generierung geografisch plausibler Adressen und Anwendung regionsspezifischer Regeln, wie z. B. korrekte Mehrwertsteuer-/TVA-Sätze für verschiedene Länder (z. B. 8,1% für die Schweiz gegenüber 19% für Deutschland).
Integrität der Geschäftslogik: Durchsetzung der numerischen und kontextuellen Kohärenz innerhalb der Rechnung. Dazu gehören mathematische Prüfungen (z. B. korrekte Summierung der Einzelposten zur Endsumme), zeitliche Logik (z. B. das Fälligkeitsdatum muss auf das Ausstellungsdatum folgen) und semantische Plausibilität. Die Pipeline stellt sicher, dass die beschriebenen Dienste kontextuell dem Geschäftstyp entsprechen. Beispielsweise stellt ein Sanitärunternehmen „Rohrreparaturdienstleistungen" in Rechnung, nicht „Softwarelizenzierung".
Der allgemeine Prozess, um dies zu erreichen, wird im Folgenden detailliert beschrieben:
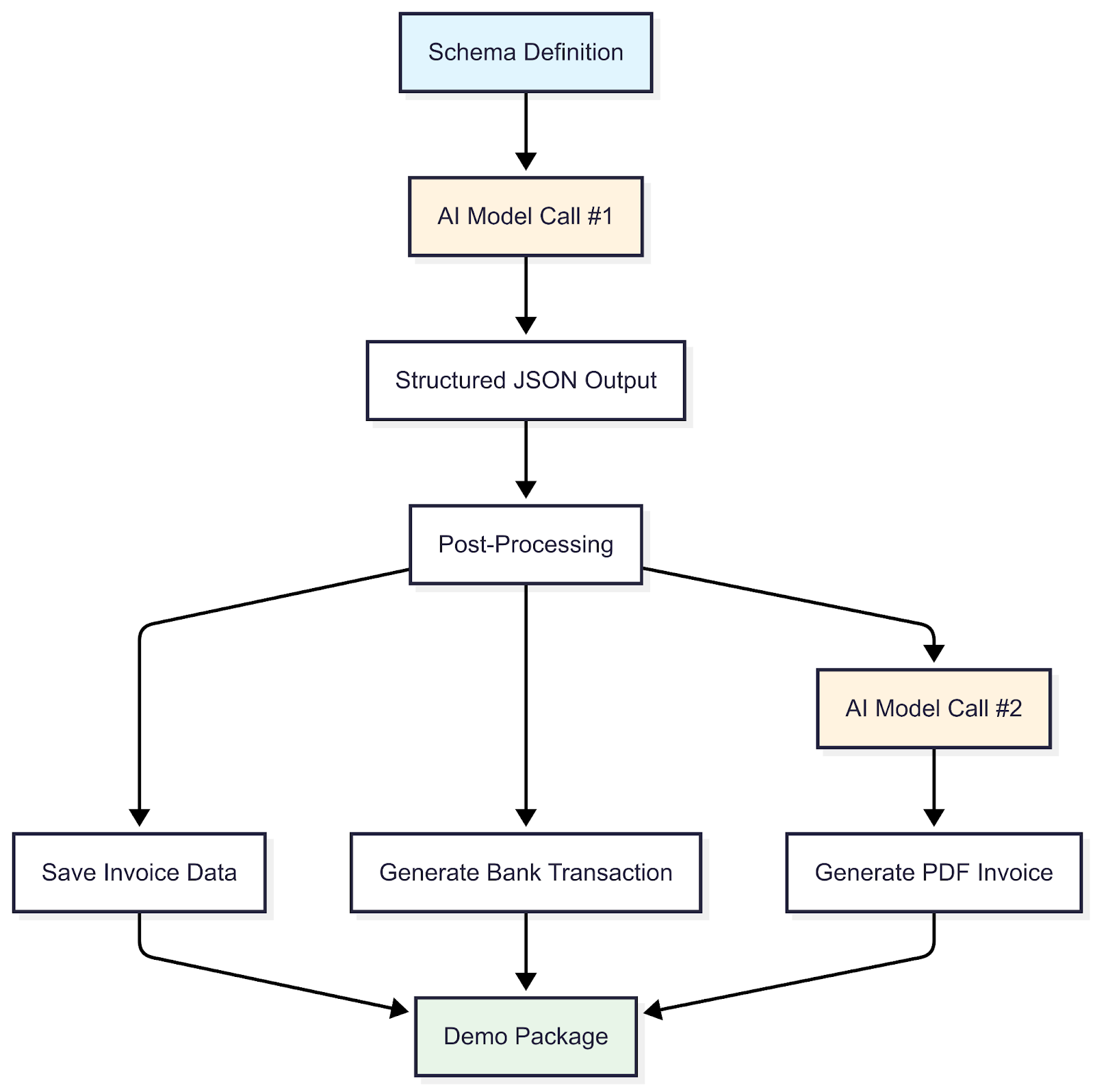
Schrittweiser Ablauf
Schemadefinition:
Der Prozess beginnt mit der Definition eines umfassenden Schemas, das als maßgeblicher Entwurf für jede Rechnung dient. Dieses Schema legt die vollständige Datenstruktur fest und definiert nicht nur die Kernkomponenten, sondern auch die erforderlichen Datentypen, Formate und logischen Einschränkungen. Dadurch wird sichergestellt, dass jede Ausgabe strukturell einwandfrei ist, bevor Daten generiert werden. Zu den wichtigsten Strukturkomponenten, die im Schema definiert sind, gehören:
- Identifikation: Rechnungsnummer und Ausstellungsdatum
- Parteien: Verkäufer- und Käuferdaten (offizielle Namen, Adressen, Umsatzsteuer-Identifikationsnummern)
- Transaktionsdetails: Einzelposten (Beschreibungen, Mengen, Einzelpreise, Mehrwertsteuersätze)
- Finanzielle Zusammenfassung: Gesamtbeträge (Zwischensumme, Mehrwertsteuer, Gesamtsumme)
- Zahlungsanweisungen: Zahlungsinformationen (IBAN, Bankdaten)
KI-Modellaufruf #1
Mit dem Schema als Leitfaden ruft die Pipeline zum ersten Mal das LLM auf, um den tatsächlichen Rechnungsinhalt zu generieren. Wir geben der KI drei Arten von Anweisungen:
Regeln zur Einhaltung der Vorschriften – Die KI muss regionale Standards einhalten: korrekte Mehrwertsteuersätze für jedes Land, gültige IBAN-Formate, korrekte Adressstrukturen usw.
Das Szenario – Welche Art von Rechnung benötigen wir? SaaS-Abrechnung, Logistikdienstleistungen, Beratungsarbeiten, Baumaterialien? Wir verwenden echte Schweizer und EU-Firmennamen (öffentlich zugänglich) statt generischer Platzhalter wie „Acme Corp", um Demos nachvollziehbarer und überzeugender zu gestalten.
Personas – Um echte Abwechslung zu bieten, verwenden wir Personas wie „Schweizer KMU-Inhaber:in" oder „freiberufliche:r deutsche:r Designer:in". Jede Persona prägt den Rechnungskontext: Ein Schweizer KMU erhält CHF-Rechnungen auf Deutsch oder Französisch für Dienstleistungen wie „IT-Support" oder „Buchhaltungsdienstleistungen", während eine freiberufliche Person aus Deutschland EUR-Rechnungen für „Logodesign" oder „Webentwicklung" erhält. Das schafft glaubwürdige Vielfalt, anstatt nur Zahlen zu randomisieren.
Strukturierte JSON-Ausgabe
Es ist schwierig, ein LLM dazu zu bringen, Daten zu erstellen, die dem zuvor definierten Schema entsprechen. Sie wurden entwickelt, um Text zu schreiben, nicht um Formulare auszufüllen. Wir nutzen die Funktion des Modells zum Aufrufen von Funktionen: Wir übergeben unser Rechnungsschema als Funktion, die das LLM aufrufen muss. Das Modell behandelt es so, als würde es ein Tool aufrufen, was es zwingt, Daten in unserer exakten Struktur zurückzugeben: jedes Feld, jeder Datentyp, genau wie angegeben.
Das bedeutet, dass wir eine strukturierte JSON-Datei mit allen Rechnungsdetails (Einzelposten, Beträge, Umsatzsteuer-Aufschlüsselungen, Unternehmensinformationen) zurückerhalten, die bereits dem Schema entspricht. Wir validieren die Ausgabe immer noch, um Sonderfälle zu erkennen, aber dieser Ansatz reduziert die Anzahl der Fehler erheblich, verglichen mit der Aufforderung an das LLM, „bitte gültiges JSON auszugeben".
Nachbearbeitung
Die validierten Daten werden verbessert, um Realismus und Nützlichkeit zu erhöhen, zum Beispiel:
- Gültige IBANs werden mithilfe eines speziellen Zufalls-IBAN-Generators generiert, der Bankformaten entspricht und realistische Zahlungssimulationen ermöglicht.
- Zeitstempel werden hinzugefügt, um die zeitliche Genauigkeit widerzuspiegeln und den realen Rechnungsstellungspraktiken zu entsprechen.
- Eindeutige IDs werden jeder Rechnung zugewiesen, um die Rückverfolgbarkeit und das effiziente Datenmanagement innerhalb der Pipeline und nachgelagerter Anwendungen zu gewährleisten.
Rechnungsdaten speichern
Die erweiterten Rechnungen werden als JSON-Dateien gespeichert, die für eine nahtlose Integration in Datenbanksysteme strukturiert sind und das Speichern und Abrufen erleichtern.
Banktransaktion generieren
Für jede Rechnung wird mit TypeScript programmgesteuert eine entsprechende Banktransaktion generiert. In ihrer Grundform werden Transaktionsdetails (z. B. Betrag, Zahler-/Zahlungsempfänger-IBANs) perfekt aus den Rechnungsdaten abgeleitet. Dies gewährleistet einen sauberen Eins-zu-Eins-Abgleich, ideal für erste Abstimmungstests und die Validierung von Kernabläufen.
Um jedoch reale Bedingungen wirklich simulieren zu können, beinhaltet eine geplante Erweiterung die Einführung von kontrollierten Abweichungen in diese Transaktionen. Dazu würden häufig auftretende Datenfehler (wie leicht unterschiedliche Zahlungsdaten, gekürzte Angaben zum Zahler oder kryptische Referenzfelder) programmatisch simuliert, um die oft chaotische und unvorhersehbare Natur der Rohdaten von Kontoauszügen originalgetreuer abzubilden und so die Robustheit der Abstimmungslogik einem Stresstest zu unterziehen.
KI-Modellaufruf #2
LLMs werden erneut verwendet, um HTML/CSS-Code zu generieren und visuell realistische Rechnungslayouts zu erstellen, die die strukturierten JSON-Daten widerspiegeln.
PDF-Rechnung generieren
Das validierte HTML wird in ein sauberes, digital natives PDF im A4-Format gerendert. Diese Ausgabe eignet sich ideal für Standardtests, z. B. zur Überprüfung des Renderings der Benutzeroberfläche und zur Bestätigung der korrekten Datendarstellung für die direkte Übermittlung an den Kunden.
Um die Daten jedoch realistischer zu machen, könnte eine zukünftige Erweiterung die Einführung einer „Degradationsschicht" beinhalten. Viele Rechnungen aus der realen Welt kommen nicht als makellose Dateien an, sondern als Smartphone-Fotos oder Scans von geringer Qualität. Diese Erweiterung würde solche Szenarien simulieren, indem die Rechnung programmgesteuert als leicht verzerrtes Bild mit niedrigerer Auflösung in das PDF eingebettet wird. Obwohl dies derzeit keine Priorität hat, wäre dies von unschätzbarem Wert für die akademische Erforschung oder für Stresstests der wahren Belastbarkeit von Pipelines zur optischen Zeichenerkennung (OCR) und automatisierten Datenextraktion. Dies würde sie mit den unvollkommenen Eingaben konfrontieren, mit denen sie bei der Produktion unweigerlich zu tun hätte.
Demo-Paket
Im letzten Schritt werden alle zugehörigen Artefakte (die strukturierten JSON-Rechnungsdaten, die entsprechenden Banktransaktionen und die visuellen PDF-Rechnungen) in einem einzigen, eigenständigen Zip-Paket konsolidiert. Dies dient dazu, die Datenkohärenz zu gewährleisten und deren Verwendung in nachgelagerten Prozessen zu vereinfachen. Anstatt sich mit losen Dateien zu befassen, erhalten Entwickelnde oder QA-Spezialist:innen ein vollständiges, atomares Testset. Dies ist für mehrere Workflows von entscheidender Bedeutung:
Reproduzierbare Fehlerberichte: Wenn ein Test fehlschlägt, können Entwickelnde das genaue Paket an einen Fehlerbericht anhängen und sich damit den vollständigen Datensatz (visuell, strukturell und transaktional) zur Verfügung stellen, der das Problem verursacht hat, wodurch jegliche Unklarheit beseitigt wird.
Durchgängiges Testen: QA-Spezialist:innen können das Paket als zentrale Informationsquelle verwenden. Sie können ein PDF auf die Benutzeroberfläche hochladen und dann anhand der entsprechenden Transaktionsdaten aus demselben Paket überprüfen, ob das Backend es korrekt verarbeitet hat.
Versionierte Testdaten: Das Paket fungiert als versioniertes, portables Asset. Auf eine automatisierte Testsuite kann verwiesen werden (test-run-v1.2.zip), um sicherzustellen, dass die Tests immer anhand eines bekannten, konsistenten und vollständigen Datensatzes ausgeführt werden.
Ergebnisse
Der Erfolg der Pipeline wird nicht an den Dateien gemessen, die sie erstellt, sondern an den Funktionen, die sie ermöglicht. Das Hauptergebnis ist ein grundlegender Wandel vom Paradigma der Datenknappheit hin zum Paradigma der On-Demand-Datenfülle zum Testen und Demonstrieren. Das greifbare Ergebnis ist ein konsistentes Angebot an kohärenten Testpaketen, die jeweils schemakonforme Rechnungen, abgeglichene Banktransaktionen und originalgetreue PDF-Darstellungen enthalten. Dies hat zweifache strategische Auswirkungen:
Verbesserte Produktstabilität: Entwicklungsteams können jetzt nicht mehr nur anhand eines kleinen, sich wiederholenden Datensatzes testen. Sie können kontinuierliche, automatisierte Tests anhand einer praktisch unbegrenzten Vielfalt verschiedener Szenarien durchführen, um Grenzfälle aufzudecken und sicherzustellen, dass die Anwendung unter realen Bedingungen robust ist.
Wirkungsvolle Vorführungen: Produktvorführungen beschränken sich nicht mehr auf dieselben generischen Beispiele. Die Möglichkeit, maßgeschneiderte, kontextrelevante Rechnungen im Handumdrehen zu erstellen, macht Präsentationen überzeugender und direkt auf die Bedürfnisse potenzieller Kunden ausgerichtet.
Letztlich führt diese neue Fähigkeit zur Bereitstellung eines qualitativ hochwertigeren Finanzprodukts, das gründlicher geprüft wurde, nachweislich zuverlässig ist und nachweislich die Komplexität bewältigt, mit der es bei der Produktion konfrontiert sein wird.
Einschränkungen und Herausforderungen
Trotz ihrer Wirksamkeit weist die Pipeline erhebliche Einschränkungen auf.
Erstens können die zur Datengenerierung verwendeten LLMs Verzerrungen in ihren Trainingsdaten widerspiegeln und möglicherweise bestimmte Branchen (z. B. IT-Dienstleistungen) oder Produkttypen (z. B. Softwareabonnements) überrepräsentieren. Um dem entgegenzuwirken, könnten wir einen Diversitätsindex (z. B. den Gini-Simpson-Index) verwenden, um die Verteilung der Geschäftstypen und Produktkategorien im generierten Datensatz zu bewerten und die Aufforderungen dahingehend zu verfeinern, dass unterrepräsentierte Sektoren wie das Baugewerbe oder das Gastgewerbe mit einbezogen werden.
Zweitens stellt die Schemavalidierung mit einem JSON-Validator zwar die Einhaltung der Vorschriften sicher, es treten jedoch weiterhin seltene Fehler auf, wie z. B. falsche Mehrwertsteuersätze (z. B. 8,1% statt 8,1% für Schweizer Standardsätze) oder unplausible Firmennamen. Diese werden durch iteratives Prompt-Tuning und sekundäre Validierungsprüfungen minimiert.
Drittens ist die Pipeline für schweizerische/europäische Standards optimiert, die spezifische Mehrwertsteuerstrukturen und IBAN-Anforderungen beinhalten. Die Ausweitung auf andere Regionen wie Nordamerika (mit bundesstaatsspezifischen Umsatzsteuern) oder Asien (mit Rechnungsformaten in mehreren Währungen) erfordert umfangreiche Schemaänderungen und regionsspezifisches Prompt-Engineering. Beispielsweise benötigen US-Rechnungen möglicherweise Felder für staatliche Steuerbefreiungen, was dynamische Schemaaktualisierungen erforderlich macht. Künftige Arbeiten werden modularen Schemadesigns Vorrang einräumen, um die Skalierbarkeit zu verbessern.
Viertens müssen die in der Pipeline enthaltenen Parameter fortlaufend gewartet werden. Steuersätze, regulatorische Anforderungen und Rechnungsstandards ändern sich im Laufe der Zeit, insbesondere in verschiedenen Ländern. Diese Parameter müssten regelmäßig, wahrscheinlich auf jährlicher Basis, aktualisiert werden, um sicherzustellen, dass die generierten Daten korrekt bleiben und den geltenden Vorschriften in den einzelnen Zielregionen entsprechen.
Fazit
Unsere LLM-gesteuerte Pipeline verändert die Art und Weise, wie wir Finanzanwendungen testen und demonstrieren. Indem sie bei Bedarf vielfältige, konforme und realistische Datensätze generiert, ermöglicht sie eine gründliche Systemvalidierung, mit der eine manuelle Datenerstellung einfach nicht mithalten kann.
Wir erweitern die Pipeline, um globale Rechnungsformate mithilfe modularer Schemata abzuwickeln, von US-Umsatzsteuersystemen bis hin zu asiatischen Anforderungen für mehrere Währungen. Wir entwickeln auch standardisierte APIs, um die synthetische Datengenerierung direkt in Entwicklungsabläufe zu integrieren.
Die praktischste Anwendung, an der wir arbeiten, sind öffentliche Demo-Umgebungen. Da die Pipeline vollständig synthetische Daten garantiert, können wir jetzt etwas anbieten, das vorher nicht möglich war: Live-Demo-Konten mit echter Funktionalität. Unternehmer:innen, die Sway testen, oder Treuhänder:innen, die Kunden die Plattform zeigen, können die tatsächlichen Funktionen anhand vollständiger Datensätze erkunden. Keine redigierten Felder, kein Platzhaltertext. Sie können sich durch Rechnungen klicken, Berichte erstellen und sehen, wie die Plattform ihre Arbeitsabläufe handhabt – und das alles, ohne das Risiko einzugehen, vertrauliche Informationen preiszugeben.
Das ist der Vorteil synthetischer Daten, die richtig gemacht werden. Sie sehen echt aus, verhalten sich wie echte Daten und ermöglichen es den Menschen, das Produkt richtig zu bewerten.
---
Mit KI erstelltes Titelbild.