
Introduction
La création manuelle de factures pour tester des applications financières, telles que les logiciels de comptabilité et les plateformes de traitement des paiements, est un processus chronophage et laborieux qui risque par ailleurs d'exposer des données sensibles. Par exemple, les logiciels de comptabilité tels que Xero ou Bexio nécessitent des documents de facturation réalistes pour tester les capacités d'extraction et d'analyse des données. Notre pipeline automatisé, alimenté par de grands modèles de langage (LLM) tels que Gemini et Claude, génère des factures réalistes conformes aux normes de conformité régionales.
La création manuelle de 100 factures conformes représente un défi considérable. Cette tâche est estimée à 50 heures, en supposant 30 minutes par facture pour la collecte des données, le formatage et les contrôles de conformité. Par conséquent, les équipes de développement sont obligées de réutiliser un petit ensemble statique de données de test, ce qui ne permet pas d'exposer un système aux divers scénarios auxquels il sera confronté en production.
Notre pipeline modifie cette dynamique. Le véritable avantage ne réside pas dans l'accélération d'un processus existant, mais dans l'ouverture d'un nouveau processus : la capacité de générer des ensembles de données volumineux et conformes à la demande. Cela permet aux développeurs d'effectuer des tests en continu avec de nouvelles données pour chaque version, de tester des cas limites complexes et de créer quotidiennement des démonstrations clients dynamiques à fort impact. En automatisant ce flux de travail, notre solution élimine également les erreurs manuelles (par exemple, des taux de TVA incorrects, des IBAN mal formatés) et les risques de conformité inhérents à une approche manuelle. Il en résulte un changement important en matière d'assurance qualité : au lieu de publier des logiciels testés sur une poignée de cas prévisibles, les équipes peuvent désormais fournir des applications financières dont la robustesse, la conformité et la résilience ont été prouvées par rapport à un large éventail de scénarios réels.
Pourquoi les données synthétiques sont importantes
Les applications financières telles que les logiciels de comptabilité et les plateformes de paiement ont besoin de données de test fiables pour s'assurer qu'elles fonctionnent correctement et répondent aux exigences réglementaires. La création manuelle de données synthétiques n'est pas évolutive, comme nous l'avons déjà établi. Les données réelles sur les clients ne sont pas non plus une solution. Même lorsque les clients donnent leur autorisation, les mesures de sécurité nécessaires pour prévenir les violations et protéger l'intégrité des données peuvent rendre les environnements de test inutilement complexes et difficiles à gérer. La génération de données synthétiques permet de résoudre ce problème tout en offrant des avantages clés :
Tests de performance et de résistance évolutifs : Le pipeline permet de générer des données à un volume et à une vitesse impossibles à reproduire manuellement. Cela est essentiel pour tester les limites du système et découvrir les goulots d'étranglement en termes de performances. Par exemple, vous pouvez simuler un cycle de clôture mensuelle avec des milliers de factures volumineuses pour tester le débit de la passerelle de paiement, ou remplir un compte utilisateur unique avec plus de 10 000 factures pour vérifier que les fonctionnalités de l'interface utilisateur telles que la recherche, le filtrage et la pagination restent performantes et ne se dégradent pas en cas de charge réaliste.
Validation complète de l'intégrité des données : Une facture synthétique unique constitue une référence cohérente pour valider l'ensemble du parcours des données sur l'ensemble de votre pile d'applications. Par exemple, une facture générée pour 99,50 CHF peut être utilisée simultanément pour :
- Tester la précision de l'analyse en vérifiant que votre analyseur de factures extrait correctement tous les champs (montant, date, fournisseur, rubriques) du PDF.
- Valider son rendu visuel et sa mise en forme dans l'interface utilisateur frontale.
- Vérifier que l'API principale traite correctement le montant et le stocke avec précision dans la base de données.
- Vérifier que le module de comptabilité calcule et enregistre correctement la taxe correspondante (par exemple, 8,1 %) dans le grand livre.
Cela garantit une intégrité parfaite des données, du pixel au registre, une tâche notoirement difficile et sujette aux erreurs lors de l'utilisation de données séparées et déconnectées pour chaque couche.
Atténuation complète des risques : Les données synthétiques éliminent les risques liés au traitement des informations réelles des clients dans les environnements de test. Cette protection va au-delà de la simple conformité réglementaire à des lois telles que le RGPD et la LPD suisse. Même lorsque les clients donnent leur consentement explicite pour que leurs données soient utilisées à des fins de test, les risques opérationnels liés à une fuite accidentelle, à un environnement mal configuré ou à une exposition involontaire à un service tiers persistent. En créant des données structurellement réalistes mais entièrement fictives, notre approche sécurise l'environnement de test dès la conception, en séparant totalement les activités de développement des données de production sensibles.
Cette approche transforme la génération de factures d'une tâche manuelle fastidieuse en un outil automatisé qui accélère les délais de développement tout en respectant les normes de sécurité des données.
Fonctionnement du pipeline
Le pipeline, implémenté dans TypeScript, suit un flux structuré allant de la définition du schéma à la création du package de démonstration, en tirant parti des fonctionnalités d'un LLM. Ce flux de travail génère des données de facturation synthétiques qui ne sont pas simplement aléatoires, mais conformes à un ensemble strict de normes du monde réel afin de garantir leur utilité et leur réalisme. Plus précisément, le pipeline assure la conformité dans plusieurs domaines clés :
Conformité structurelle et de format : S'assurer que les données telles que les IBAN, les QR-IBAN et les numéros de référence respectent leurs spécifications officielles (par exemple, ISO 13616 pour les IBAN).
Cohérence régionale et juridique : Générer des adresses géographiquement plausibles et appliquer des règles spécifiques à la région, telles que des taux de TVA corrects pour différents pays (par exemple, 8,1 % pour la Suisse contre 19 % pour l'Allemagne).
Intégrité de la logique métier : Renforcer la cohérence numérique et contextuelle de la facture. Cela inclut les vérifications mathématiques (par exemple, la somme des rubriques correspond correctement au total final), la logique temporelle (par exemple, la date d'échéance doit suivre la date d'émission) et la plausibilité sémantique. Le pipeline garantit que les services décrits sont adaptés au contexte du type d'entreprise. Par exemple, une entreprise de plomberie facturera les « services de réparation de tuyaux », et non les « licences logicielles ».
Le processus de haut niveau pour y parvenir est détaillé ci-dessous :
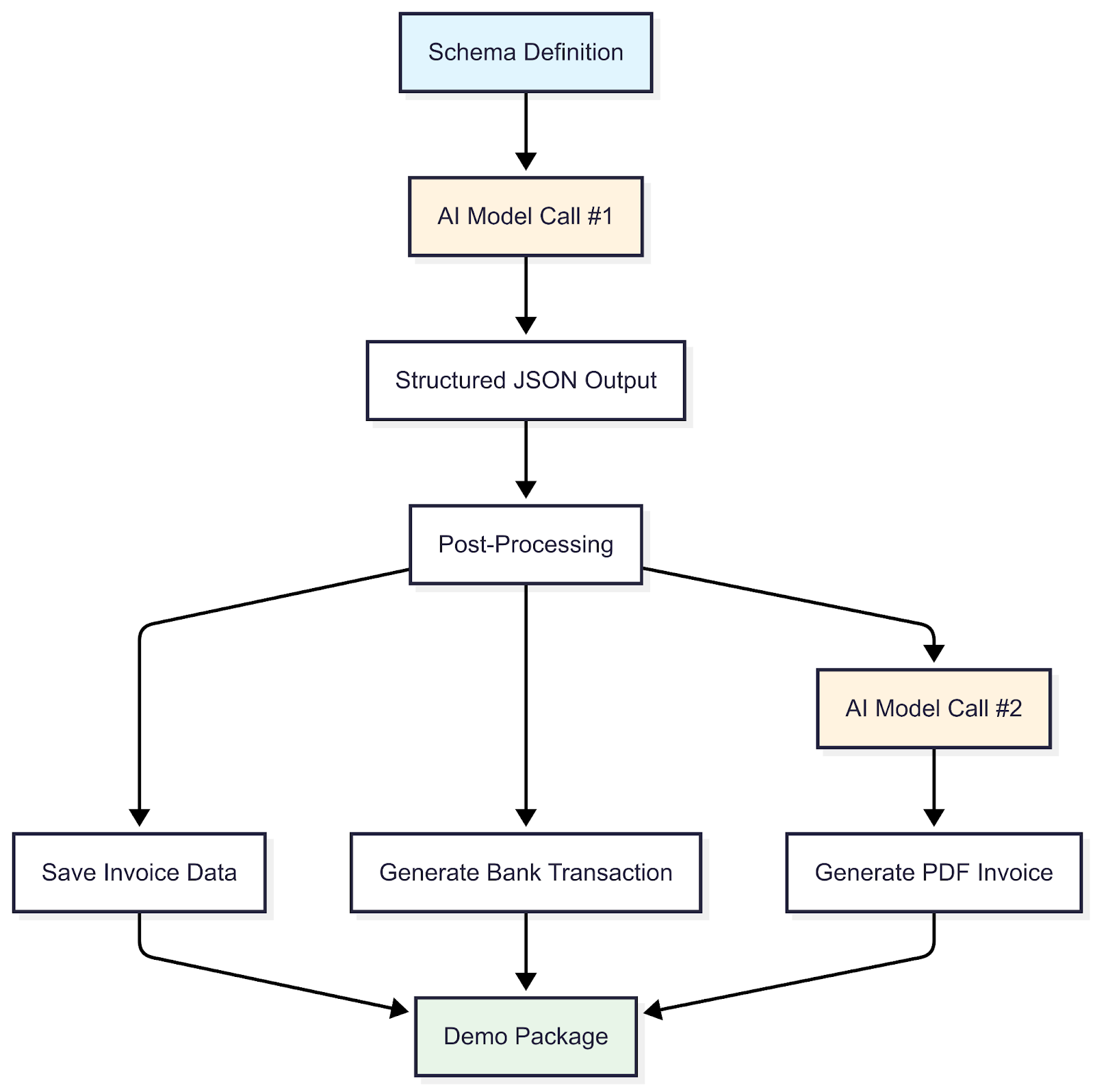
Détail des étapes
Définition du schéma
Le processus commence par la définition d'un schéma complet qui sert de modèle officiel pour chaque facture. Ce schéma établit la structure complète des données, en définissant non seulement les composants principaux, mais également les types de données, les formats et les contraintes logiques requis. Cela garantit que chaque sortie est structurellement saine avant la génération de données. Les principaux composants structurels définis dans le schéma sont les suivants :
- Identification : numéro de facture et date d'émission
- Parties : coordonnées du vendeur et de l'acheteur (noms légaux, adresses, numéros de TVA)
- Détails de la transaction : rubriques (descriptions, quantités, prix unitaires, taux de TVA)
- Résumé financier : montants totaux (sous-total, TVA, total général)
- Instructions de paiement : informations de paiement (IBAN, coordonnées bancaires)
Appel à modèles d'IA #1
Avec le schéma comme guide, le pipeline fait son premier appel au LLM pour générer le contenu réel de la facture. Nous donnons à l'IA trois types d'instructions :
Règles de conformité - L'IA doit respecter les normes régionales : taux de TVA corrects pour chaque pays, formats IBAN valides, structures d'adresses appropriées, etc.
Le scénario - De quel type de facture avons-nous besoin ? Facturation SaaS, services logistiques, travaux de conseil, matériaux de construction ? Nous utilisons de vrais noms commerciaux suisses et européens (accessibles au public) plutôt que des espaces réservés génériques tels que « Acme Corp » pour rendre les démos plus pertinentes et plus convaincantes.
Personnages - Pour obtenir une réelle variété, nous utilisons des personnages tels que « propriétaire d'une PME suisse » ou « designer allemand indépendant ». Chaque personnage façonne le contexte de facturation : une PME suisse reçoit des factures en francs suisses en allemand ou en français pour des services tels que le « support informatique » ou les « services de comptabilité », tandis qu'un indépendant allemand reçoit des factures en euros pour la « conception de logo » ou le « développement Web ». Cela crée une diversité crédible au lieu de simplement randomiser les chiffres.
Sortie JSON structurée
Il est difficile de faire en sorte qu'un LLM produise des données correspondant au schéma que nous avons défini précédemment. Les LLM sont conçus pour générer du texte libre, pas pour produire des données structurées. Nous utilisons la capacité d'appel de fonctions du modèle : nous transmettons notre schéma de facture en tant que fonction que le LLM doit appeler. Le modèle le traite comme si vous invoquiez un outil, ce qui l'oblige à renvoyer les données dans notre structure exacte : chaque champ, chaque type de données, exactement comme spécifié.
Cela signifie que nous récupérons un fichier JSON structuré contenant tous les détails de la facture (rubriques, montants, ventilation de la TVA, informations sur l'entreprise) qui est déjà conforme au schéma. Nous continuons à valider la sortie pour rattraper les cas les plus urgents, mais cette approche réduit considérablement les erreurs par rapport au fait de demander au LLM de « veuillez générer un JSON valide ».
Post-traitement
Les données validées sont améliorées pour améliorer le réalisme et l'utilité, par exemple :
IBAN valides sont générés à l'aide d'un générateur d'IBAN aléatoire spécialisé, conforme aux formats bancaires, permettant des simulations de paiement réalistes.
Horodatages sont ajoutés pour refléter la précision temporelle, conformément aux pratiques de facturation réelles.
Identifiants uniques sont attribués à chaque facture à des fins de traçabilité et de gestion efficace des données au sein du pipeline et des applications en aval.
Enregistrer les données de facturation
Les factures améliorées sont enregistrées sous forme de fichiers JSON, structurés pour une intégration transparente avec les systèmes de base de données, facilitant ainsi le stockage et la récupération.
Générer une transaction bancaire
Pour chaque facture, une transaction bancaire correspondante est générée par programmation à l'aide de TypeScript. Dans sa forme de base, les détails des transactions (par exemple, le montant, les IBAN du payeur/bénéficiaire) sont parfaitement dérivés des données de facturation. Cela garantit une correspondance parfaite, idéale pour les tests de rapprochement initiaux et la validation des flux de travail de base.
Cependant, pour simuler véritablement les conditions du monde réel, une amélioration planifiée consiste à introduire un « bruit » contrôlé dans ces transactions. Cela impliquerait de simuler par programmation les imperfections courantes des données (telles que des dates de paiement légèrement différentes, des informations tronquées sur le payeur ou des champs de référence cryptés) afin de reproduire plus fidèlement la nature souvent chaotique et imprévisible des flux de relevés bancaires bruts, testant ainsi la robustesse de la logique de rapprochement.
Appel à modèles d'IA #2
Les LLM sont à nouveau utilisés pour générer du code HTML/CSS, produisant des mises en page de facture visuellement réalistes qui reflètent les données JSON structurées.
Générer une facture au format PDF
Le code HTML validé est rendu dans un PDF numérique natif propre au format A4. Cette sortie est idéale pour les tests standard, tels que la vérification du rendu de l'interface utilisateur et la confirmation de la présentation correcte des données pour une livraison directe au client.
Cependant, pour rendre les données plus réalistes, une extension future pourrait impliquer l'introduction d'une couche de « dégradation ». De nombreuses factures réelles arrivent non pas sous forme de fichiers vierges, mais sous forme de photos prises sur un smartphone ou de scans de faible qualité. Cette amélioration permettrait de simuler de tels scénarios en intégrant par programmation la facture sous la forme d'une image légèrement asymétrique de faible résolution dans le PDF. Bien qu'il ne s'agisse pas d'une priorité actuelle, cela serait d'une valeur inestimable pour la recherche académique ou pour tester la véritable résilience de tout pipeline de reconnaissance optique de caractères (OCR) et d'extraction de données automatisée, en le confrontant à des données imparfaites auxquelles il serait inévitablement confronté en production.
Package de démonstration
La dernière étape regroupe tous les artefacts connexes (les données de facturation JSON structurées, les transactions bancaires correspondantes et les factures PDF visuelles) dans un package zip unique et autonome. L'objectif est de garantir la cohérence des données et de simplifier leur utilisation dans les processus en aval. Au lieu de gérer des fichiers dispersés, un développeur ou un ingénieur QA reçoit un kit de test complet et autonome. Ceci est essentiel pour plusieurs flux de travail :
Rapports de bugs reproductibles : lorsqu'un test échoue, un développeur peut joindre le package exact à un rapport de bug, en lui fournissant l'ensemble complet des données (visuelles, structurelles et transactionnelles) à l'origine du problème, éliminant ainsi toute ambiguïté.
Tests de bout en bout : un ingénieur QA peut utiliser le package comme référence unique. Il peut télécharger un PDF dans l'interface utilisateur, puis utiliser les données de transaction correspondantes provenant du même package pour vérifier que le backend les a traitées correctement.
Données de test versionnées : le package agit comme un ensemble de données versionné et portable. Une suite de tests automatisée peut être pointée vers test-run-v1.2.zip, en veillant à ce que les tests soient toujours exécutés sur un ensemble de données connu, cohérent et complet.
Résultats
Le succès du pipeline ne se mesure pas aux fichiers qu'il crée, mais aux fonctionnalités qu'il débloque. Le résultat principal est un changement fondamental d'un paradigme de rareté des données à un paradigme d'abondance de données à la demande pour les tests et les démonstrations. Le résultat tangible est un approvisionnement constant de packages de test cohérents, chacun contenant des factures conformes aux schémas, des transactions bancaires correspondantes et des représentations PDF haute fidélité. L'impact stratégique de cette initiative est double :
Robustesse améliorée des produits : les équipes de développement peuvent désormais aller au-delà des tests sur un petit ensemble de données répétitif. Elles peuvent exécuter des tests continus et automatisés sur un flux pratiquement illimité de scénarios divers, découvrir des cas limites et garantir la résilience de l'application dans des conditions réelles.
Démonstrations à fort impact : les démonstrations de produits ne se limitent plus aux mêmes exemples génériques. La possibilité de générer à la volée des factures personnalisées et pertinentes en fonction du contexte rend les présentations plus convaincantes et directement adaptées aux besoins des clients potentiels.
En fin de compte, cette nouvelle capacité conduit à la fourniture d'un produit financier de meilleure qualité, qui est contrôlé de manière plus approfondie, dont la fiabilité est démontrée et qui a prouvé sa capacité à gérer la complexité à laquelle il sera confronté en production.
Limites et défis
Malgré son efficacité, le pipeline présente des limites notables.
Tout d'abord, les LLM utilisés pour la génération de données peuvent refléter des biais dans leurs données de formation, pouvant surreprésenter certains secteurs (par exemple, les services informatiques) ou certains types de produits (par exemple, les abonnements logiciels). Pour y remédier, nous pourrions appliquer un indice de diversité (par exemple, l'indice de Gini-Simpson) pour évaluer la distribution des types d'entreprises et des catégories de produits dans l'ensemble de données généré et affiner les instructions pour inclure les secteurs sous-représentés tels que la construction ou l'hôtellerie.
Deuxièmement, si la validation des schémas à l'aide d'un validateur JSON garantit la conformité, de rares erreurs persistent, telles que des taux de TVA incorrects (par exemple, 8,1 % au lieu de 7,7 % pour les taux suisses standard) ou des noms commerciaux peu plausibles. Ceux-ci sont minimisés grâce à un ajustement itératif des prompts et à des contrôles de validation secondaires.
Troisièmement, le pipeline est optimisé pour les normes suisses et européennes, qui incluent des structures de TVA spécifiques et des exigences IBAN. Son extension à d'autres régions, telles que l'Amérique du Nord (avec des taxes de vente spécifiques à chaque État) ou l'Asie (avec des formats de facture multidevises), nécessite d'importantes modifications du schéma et une adaptation des prompts par région. Par exemple, les factures américaines peuvent nécessiter des champs pour les exonérations fiscales nationales, ce qui nécessite des mises à jour dynamiques des schémas. Les travaux futurs donneront la priorité aux conceptions de schémas modulaires afin d'améliorer l'évolutivité.
Quatrièmement, les contraintes inhérentes au pipeline nécessitent une maintenance continue. Les taux d'imposition, les exigences réglementaires et les normes de facturation évoluent au fil du temps, en particulier d'un pays à l'autre. Ces paramètres nécessiteraient des mises à jour régulières, probablement sur une base annuelle, pour garantir que les données générées restent exactes et conformes aux réglementations en vigueur dans chaque région cible.
Conclusion
Notre pipeline piloté par les LLM change la façon dont nous testons et faisons des démonstrations d'applications financières. En générant des ensembles de données diversifiés, conformes et réalistes à la demande, il permet le type de validation complète du système que la création manuelle de données ne peut tout simplement pas égaler.
Nous élargissons notre portefeuille pour gérer les formats de factures mondiaux grâce à des schémas modulaires, allant des systèmes de taxe de vente américains aux exigences multidevises asiatiques. Nous développons également des API standardisées pour intégrer la génération de données synthétiques directement dans les flux de développement.
L'application la plus pratique sur laquelle nous travaillons concerne les environnements de démonstration. Parce que le pipeline garantit des données entièrement synthétiques, nous pouvons désormais proposer quelque chose qui n'était pas possible auparavant : des comptes de démonstration avec de véritables fonctionnalités. Les entrepreneurs ou partenaires testant Sway ou les fiduciaires présentant la plateforme à leurs clients pourront explorer les fonctionnalités réelles à l'aide d'ensembles de données complètes. Pas de champs expurgés, pas de texte d'espace réservé. Les utilisateurs peuvent consulter les factures, générer des rapports et voir comment la plateforme gère leurs flux de travail, le tout sans aucun risque d'exposer des informations sensibles.
Voilà tout l'avantage des données synthétiques de qualité : elles ont l'air réelles, peuvent être utilisées pour des cas d'usage concrets et permettent aux utilisateurs d'évaluer correctement le produit.
---
Photo de couverture créée avec l'IA.