
Introduction
Manual invoice creation for testing financial applications, such as accounting software and payment processing platforms, is a labor-intensive process that consumes significant time and resources while risking exposure of sensitive data. For instance, accounting softwares like Xero or Bexio require realistic invoice documents to test data extraction and parsing capabilities. Our automated pipeline, powered by Large Language Models (LLMs) such as Gemini and Claude, generates realistic invoices that adhere to regional compliance standards. The prospect of manually creating 100 compliant invoices is prohibitive. This task is estimated at 50 hours, assuming 30 minutes per invoice for data gathering, formatting, and compliance checks. Consequently, development teams are forced to reuse a small, static set of test data, which fails to expose a system to the diverse scenarios it will face in production.
Our pipeline changes this dynamic. The true advantage lies not in accelerating an old process, but in unlocking a new one: the ability to generate vast, and compliant datasets on demand. This enables developers to run continuous tests with fresh data for every build, stress-test complex edge cases, and create dynamic, high-impact client demos daily. By automating this workflow, our solution also eliminates the manual errors (e.g., incorrect VAT rates, misformated IBANs) and compliance risks inherent in a manual approach. The result is an important shift in quality assurance: instead of releasing software tested against a handful of predictable cases, teams can now deliver financial applications proven to be robust, compliant, and resilient against a vast spectrum of real-world scenarios.
Why Synthetic Data Matters
Financial applications like accounting software and payment platforms need reliable testing data to ensure they function correctly and meet regulatory requirements. Manual creation of synthetic data doesn't scale, as we've already established. Real customer data isn't a solution either. Even when customers give permission, the security measures needed to prevent breaches and protect data integrity could make test environments unnecessarily complex and difficult to maintain. Generating synthetic data solves this problem while delivering key benefits:
- Scalable Performance & Stress Testing: The pipeline unlocks the ability to generate data at a volume and velocity that is impossible to replicate manually. This is essential for stress-testing system limits and discovering performance bottlenecks. For example, you can simulate a month-end billing cycle with thousands of high-volume invoices to test payment gateway throughput, or populate a single user account with 10,000+ invoices to verify that UI features like search, filtering, and pagination remain performant and do not degrade under realistic load.
- End-to-End Data Integrity Validation: A single synthetic invoice acts as a consistent "source of truth" to validate the entire data journey across your application stack. For instance, a generated invoice for 99.50 CHF can be used to simultaneously:
- Test parsing accuracy by verifying that your invoice parser correctly extracts all fields (amount, date, vendor, line items) from the PDF.
- Validate its visual rendering and formatting in the frontend UI.
- Verify that the backend API correctly processes the amount and stores it with precision in the database.
- Confirm that the accounting module correctly calculates and posts the corresponding tax (e.g., 8.1%) to the general ledger. This ensures seamless data integrity from pixel to ledger, a notoriously difficult and error-prone task when using separate, disconnected data for each layer.
- Comprehensive Risk Mitigation: Synthetic data eliminates the risks associated with handling real customer information in test environments. This protection extends beyond simple regulatory compliance with laws like GDPR and the Swiss FADP. Even when customers grant explicit consent for their data to be used in testing, the operational risks of an accidental leak, a misconfigured environment, or unintentional exposure to a third-party service persist. By creating structurally realistic but entirely fictional data, our approach makes the test environment secure by design, completely decoupling development activities from sensitive production information.
This approach transforms invoice generation from a time-consuming manual task into an automated asset that accelerates development timelines while maintaining data security standards.
Workflow Overview
The pipeline, implemented in TypeScript, follows a structured flow from schema definition to demo package creation, leveraging the capabilities of an LLMs. This workflow generates synthetic invoice data that is not merely random, but compliant with a strict set of real-world standards to ensure its utility and realism. Specifically, the pipeline enforces compliance across several key areas:
- Structural & Format Compliance: Ensuring data like IBANs, QR-IBANs, and reference numbers adhere to their official specifications (e.g., ISO 13616 for IBANs).
- Regional & Legal Coherence: Generating geographically plausible addresses and applying region-specific rules, such as correct VAT/TVA rates for different countries (e.g., 8.1% for Switzerland vs. 19% for Germany).
- Business Logic Integrity: Enforcing both numerical and contextual coherence within the invoice. This includes mathematical checks (e.g., line items summing correctly to the final total), temporal logic (e.g., the due date must follow the issue date), and semantic plausibility. The pipeline ensures that the services described are contextually appropriate for the business type. For example, a plumbing company will invoice for "Pipe Repair Services," not "Software Licensing".
The high-level process to achieve this is detailed below:
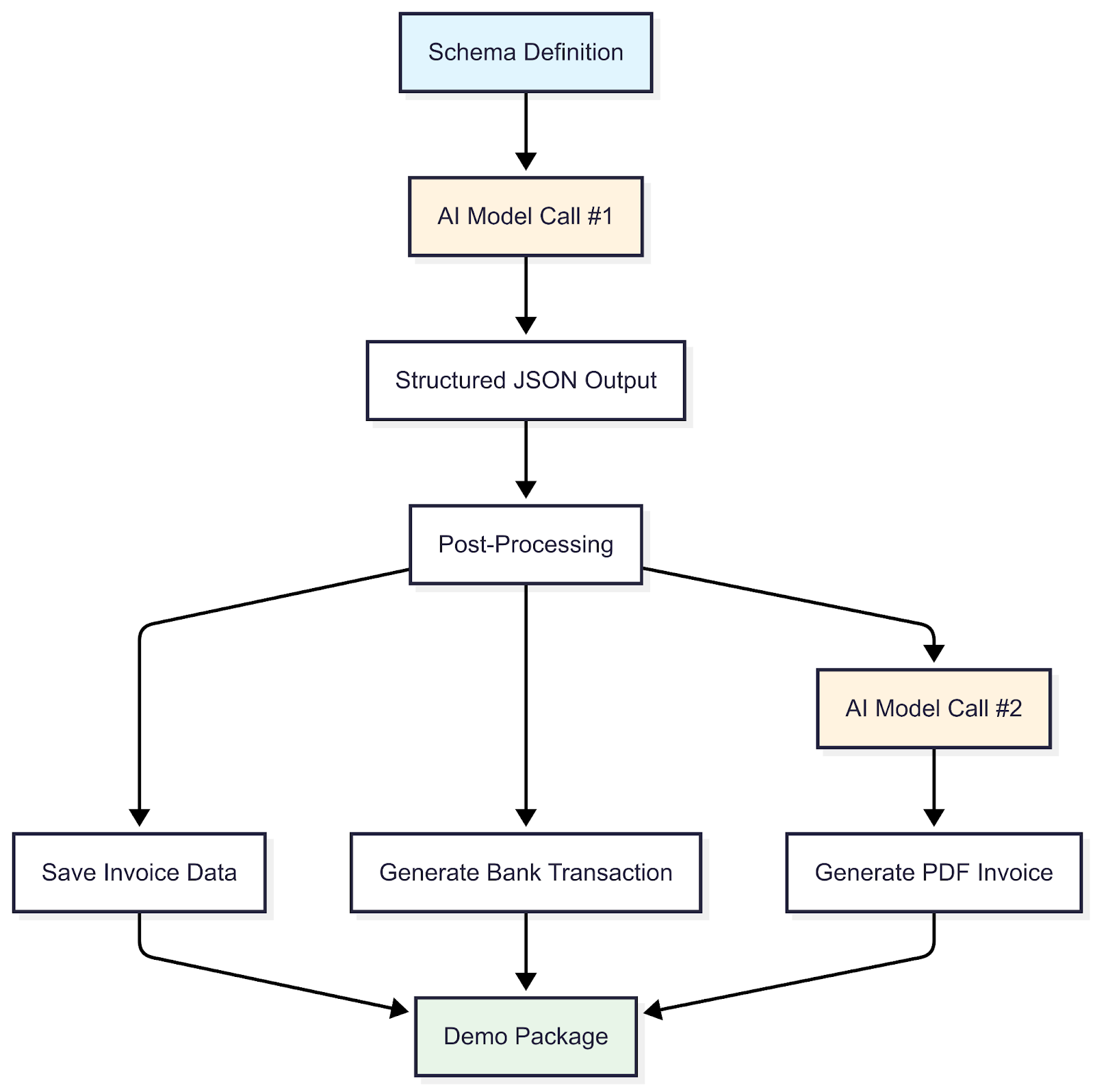
Step-by-Step Breakdown
Schema definition:
The process begins by defining a comprehensive schema that serves as the authoritative blueprint for every invoice. This schema establishes the complete data structure, defining not only the core components but also their required data types, formats, and logical constraints. This ensures that every output is structurally sound before any data is generated. Key structural components defined in the schema include:
- Identification: Invoice number and issue date
- Parties: Seller and buyer details (legal names, addresses, VAT numbers)
- Transaction Details: Line items (descriptions, quantities, unit prices, VAT rates)
- Financial Summary: Total amounts (subtotal, VAT, grand total)
- Payment Instructions: Payment information (IBAN, bank details)
AI Model Call #1
With the schema as its guide, the pipeline makes its first call to the LLM to generate the actual invoice content. We give the AI three types of instructions:
- Compliance rules - The AI must follow regional standards: correct VAT rates for each country, valid IBAN formats, proper address structures, and so on.
- The scenario - What kind of invoice do we need? SaaS billing, logistics services, consulting work, construction materials? We use real Swiss and EU business names (publicly available) rather than generic placeholders like "Acme Corp" to make demos more relatable and convincing.
- Personas - To get real variety, we use personas like "Swiss SME owner" or "freelance German designer." Each persona shapes the invoice context: a Swiss SME gets CHF invoices in German or French for services like "IT Support" or "Accounting Services," while a German freelancer gets EUR invoices for "Logo Design" or "Web Development." This creates believable diversity instead of just randomizing numbers.
Structured JSON Output
Getting an LLM to produce data that matches the schema we defined earlier is tricky. They're designed to write text, not fill out forms. We use the model's function calling capability: we pass our invoice schema as a function the LLM must call. The model treats it like invoking a tool, which forces it to return data in our exact structure: every field, every data type, exactly as specified.
This means we get back a structured JSON file with all the invoice details (line items, amounts, VAT breakdowns, company info) that already conforms to the schema. We still validate the output to catch edge cases, but this approach dramatically reduces errors compared to asking the LLM to "please output valid JSON."
Post-Processing
The validated data is enhanced to improve realism and utility, for example:
- Valid IBANs are generated using a specialized random IBAN generator compliant with banking formats, enabling realistic payment simulations.
- Timestamps are added to reflect temporal accuracy, aligning with real-world invoicing practices.
- Unique IDs are assigned to each invoice for traceability and efficient data management within the pipeline and downstream applications.
Save Invoice Data
The enhanced invoices are saved as JSON files, structured for seamless integration with database systems, facilitating storage and retrieval.
Generate Bank Transaction
For each invoice, a corresponding bank transaction is programmatically generated using TypeScript. In its baseline form, transaction details (e.g., amount, payer/payee IBANs) are perfectly derived from the invoice data. This ensures a clean one-to-one match, ideal for initial reconciliation testing and validating core workflows.
However, to truly simulate real-world conditions, a planned enhancement involves introducing controlled "noise" into these transactions. This would involve programmatically simulating common data imperfections (such as slightly mismatched payment dates, truncated payer details, or cryptic reference fields) to more faithfully replicate the often chaotic and unpredictable nature of raw bank statement feeds, thus stress-testing the robustness of the reconciliation logic.
AI Model Call #2
LLMs are utilized again to generate HTML/CSS code, producing visually realistic invoice layouts that reflect the structured JSON data.
Generate PDF Invoice
The validated HTML is rendered into a clean, A4-sized, digitally-native PDF. This output is ideal for standard testing, such as verifying UI rendering and confirming correct data presentation for direct-to-client delivery.
However, to make the data more realistic, a future extension could involve introducing a "degradation" layer. Many real-world invoices arrive not as pristine files but as smartphone photos or low-quality scans. This enhancement would simulate such scenarios by programmatically embedding the invoice as a slightly skewed, lower-resolution image within the PDF. While not a current priority, this would be invaluable for academic exploration or for stress-testing the true resilience of any Optical Character Recognition (OCR) and automated data extraction pipeline, challenging it with the imperfect inputs it would inevitably face in production.
Demo Package
The final step consolidates all related artifacts (the structured JSON invoice data, the corresponding bank transactions, and the visual PDF invoices) into a single, self-contained zip package. The purpose of this is to guarantee data coherence and simplify its use in downstream processes. Instead of dealing with loose files, a developer or QA engineer receives a complete, atomic test set. This is critical for several workflows:
- Reproducible Bug Reports: When a test fails, a developer can attach the exact package to a bug report, giving them the complete set of data (visual, structural, and transactional) that caused the issue, eliminating any ambiguity.
- End-to-End Testing: A QA engineer can use the package as a single source of truth. They can upload a PDF to the UI, then use the corresponding transaction data from the same package to verify that the backend processed it correctly.
- Versioned Test Data: The package acts as a versioned, portable asset. An automated test suite can be pointed to
test-run-v1.2.zip, ensuring that the tests are always executed against a known, consistent, and complete dataset.
Results
The pipeline's success is measured not by the files it creates, but by the capabilities it unlocks. The primary result is a fundamental shift from a paradigm of data scarcity to one of on-demand data abundance for testing and demonstration. The tangible output is a consistent supply of coherent test packages, each containing schema-compliant invoices, matched bank transactions, and high-fidelity PDF representations. The strategic impact of this is twofold:
- Enhanced Product Robustness: Development teams can now move beyond testing against a small, repetitive dataset. They can run continuous, automated tests against a virtually limitless stream of diverse scenarios, uncovering edge cases and ensuring the application is resilient under real-world conditions.
- High-Impact Demonstrations: Product demonstrations are no longer limited to the same generic examples. The ability to generate tailored, contextually relevant invoices on the fly makes showcases more persuasive and directly aligned with prospective client needs.
Ultimately, this new capability leads to the delivery of a higher-quality financial product, one that is more thoroughly vetted, demonstrably reliable, and proven to handle the complexity it will face in production.
Limitations and Challenges
Despite its effectiveness, the pipeline has notable limitations.
First, the LLMs used for data generation may reflect biases in their training data, potentially overrepresenting certain industries (e.g., IT services) or product types (e.g., software subscriptions). To counteract this, we could apply a diversity index (e.g., Gini-Simpson index) to assess the distribution of business types and product categories in the generated dataset and refining prompts to include underrepresented sectors like construction or hospitality.
Second, while schema validation using a JSON validator ensures compliance, rare errors persist, such as incorrect VAT rates (e.g., 8.1% instead of 7.7% for standard Swiss rates) or implausible business names. These are minimized through iterative prompt tuning and secondary validation checks.
Third, the pipeline is optimized for Swiss/European standards, which include specific VAT structures and IBAN requirements. Extending it to other regions, such as North America (with state-specific sales taxes) or Asia (with multi-currency invoice formats), requires extensive schema modifications and region-specific prompt engineering. For instance, U.S. invoices may need fields for state tax exemptions, necessitating dynamic schema updates. Future work will prioritize modular schema designs to enhance scalability.
Fourth, the constraints embedded in the pipeline require ongoing maintenance. Tax rates, regulatory requirements, and invoice standards evolve over time, particularly across different countries. These parameters would need regular updates, likely on an annual basis, to ensure the generated data remains accurate and compliant with current regulations in each target region.
Conclusion
Our LLMs-driven pipeline changes how we test and demo financial applications. By generating diverse, compliant, and realistic datasets on demand, it enables the kind of thorough system validation that manual data creation simply can't match.
We're expanding the pipeline to handle global invoice formats through modular schemas, from U.S. sales tax systems to Asian multi-currency requirements. We're also building standardized APIs to integrate synthetic data generation directly into development workflows.
The most practical application we're working toward is public demo environments. Because the pipeline guarantees fully synthetic data, we can now offer something that wasn't possible before: live demo accounts with real functionality. Entrepreneurs testing Sway or fiduciaries showing the platform to clients will be able to explore actual features with complete datasets. No redacted fields, no placeholder text. They can click through invoices, run reports, and see how the platform handles their workflows, all without any risk of exposing sensitive information.
That's the advantage of synthetic data done right. It looks real, behaves like real data, and lets people evaluate the product properly.
Cover picture created with AI.